Rozdział dotyczący pojęć ma za zadanie pomóc w zrozumieniu poszczególnych składowych systemu oraz obiektów abstrakcyjnych, których Kubernetes używa do reprezentacji klastra, a także posłużyć do lepszego poznania działania całego systemu.
1 - Przegląd
Kubernetes to przenośna, rozszerzalna platforma oprogramowania open-source służąca do zarządzania zadaniami i serwisami uruchamianymi w kontenerach. Umożliwia ich deklaratywną konfigurację i automatyzację. Kubernetes posiada duży i dynamicznie rozwijający się ekosystem. Szeroko dostępne są usługi, wsparcie i dodatkowe narzędzia.
Na tej stronie znajdziesz ogólne informacje o Kubernetesie.
Kubernetes to przenośna, rozszerzalna platforma oprogramowania open-source służąca do zarządzania zadaniami i serwisami uruchamianymi w kontenerach,
która umożliwia deklaratywną konfigurację i automatyzację. Ekosystem Kubernetesa jest duży i dynamicznie się rozwija.
Usługi dla Kubernetesa, wsparcie i narzędzia są szeroko dostępne.
Nazwa Kubernetes pochodzi z języka greckiego i oznacza sternika albo pilota.
Skrót K8s powstał poprzez zastąpienie ośmiu liter pomiędzy "K" i "s".
Google otworzyło projekt Kubernetes publicznie w 2014. Kubernetes korzysta z
piętnastoletniego doświadczenia Google w uruchamianiu wielkoskalowych serwisów
i łączy je z najlepszymi pomysłami i praktykami wypracowanymi przez społeczność.
Trochę historii
Aby zrozumieć, dlaczego Kubernetes stał się taki przydatny, cofnijmy sie trochę w czasie.
Era wdrożeń tradycyjnych:
Na początku aplikacje uruchamiane były na fizycznych serwerach. Nie było możliwości separowania zasobów poszczególnych aplikacji,
co prowadziło do problemów z alokacją zasobów.
Przykładowo, kiedy wiele aplikacji jest uruchomionych na jednym fizycznym serwerze,
część tych aplikacji może zużyć większość dostępnych zasobów, powodując spowolnienie działania innych.
Rozwiązaniem tego problemu mogło być uruchamianie każdej aplikacji na osobnej maszynie.
Niestety, takie podejście ograniczało skalowanie, ponieważ większość zasobów nie była w pełni wykorzystywana,
a utrzymanie wielu fizycznych maszyn było kosztowne.
Era wdrożeń w środowiskach wirtualnych: Jako rozwiązanie zaproponowano wirtualizację, która umożliwia
uruchamianie wielu maszyn wirtualnych (VM) na jednym procesorze fizycznego serwera. Wirtualizacja pozwala
izolować aplikacje pomiędzy maszynami wirtualnymi, zwiększając w ten sposób bezpieczeństwo, jako że informacje
związane z jedną aplikacją nie są w łatwy sposób dostępne dla pozostałych.
Wirtualizacja pozwala lepiej wykorzystywać zasoby fizycznego serwera i lepiej skalować,
ponieważ aplikacje mogą być łatwo dodawane oraz aktualizowane, pozwala ograniczyć koszty sprzętu
oraz ma wiele innych zalet.
Za pomocą wirtualizacji można udostępnić wybrane zasoby fizyczne jako klaster maszyn wirtualnych "wielokrotnego użytku".
Każda maszyna wirtualna jest pełną maszyną zawierającą własny system operacyjny
pracujący na zwirtualizowanej warstwie sprzętowej.
Era wdrożeń w kontenerach: Kontenery działają w sposób zbliżony do maszyn wirtualnych,
ale mają mniejszy stopnień wzajemnej izolacji, współdzieląc ten sam system operacyjny.
Kontenery określane są mianem "lekkich". Podobnie, jak maszyna wirtualna,
kontener posiada własny system plików, udział w zasobach procesora, pamięć, przestrzeń procesów itd.
Ponieważ kontenery są definiowane rozłącznie od leżących poniżej warstw infrastruktury,
mogą być łatwiej przenoszone pomiędzy chmurami i różnymi dystrybucjami systemu operacyjnego.
Kontenery zyskały popularność ze względu na swoje zalety, takie jak:
Szybkość i elastyczność w tworzeniu i instalacji aplikacji:
obraz kontenera buduje się łatwiej niż obraz VM.
Ułatwienie ciągłego rozwoju, integracji oraz wdrażania aplikacji (Continuous development, integration, and deployment):
obrazy kontenerów mogą być budowane w sposób wiarygodny i częsty.
W razie potrzeby, przywrócenie poprzedniej wersji aplikacji jest stosunkowo łatwie (ponieważ obrazy są niezmienne).
Rozdzielenie zadań Dev i Ops: obrazy kontenerów powstają w fazie build/release,
a nie w trakcie procesu instalacji,
oddzielając w ten sposób aplikacje od infrastruktury.
Obserwowalność obejmuje nie tylko informacje i metryki z poziomu systemu operacyjnego,
ale także poprawność działania samej aplikacji i inne sygnały.
Spójność środowiska na etapach rozwoju oprogramowania, testowania i działania w trybie produkcyjnym:
działa w ten sam sposób na laptopie i w chmurze.
Możliwość przenoszenia pomiędzy systemami operacyjnymi i platformami chmurowymi: Ubuntu, RHEL, CoreOS,
prywatnymi centrami danych, największymi dostawcami usług chmurowych czy gdziekolwiek indziej.
Zarządzanie, które w centrum uwagi ma aplikacje: Poziom abstrakcji przeniesiony jest z warstwy systemu operacyjnego
działającego na maszynie wirtualnej na poziom działania aplikacji, która działa na systemie operacyjnym używając zasobów logicznych.
Luźno powiązane, rozproszone i elastyczne "swobodne" mikro serwisy: Aplikacje podzielone są na mniejsze, niezależne komponenty,
które mogą być dynamicznie uruchamiane i zarządzane -
nie jest to monolityczny system działający na jednej, dużej maszynie dedykowanej na wyłączność.
Izolacja zasobów: wydajność aplikacji możliwa do przewidzenia
Wykorzystanie zasobów: wysoka wydajność i upakowanie.
Do czego potrzebujesz Kubernetesa i jakie są jego możliwości
Kontenery są dobrą metodą na opakowywanie i uruchamianie aplikacji.
W środowisku produkcyjnym musisz zarządzać kontenerami, w których działają aplikacje i pilnować, aby nie było żadnych przerw w ich dostępności.
Przykładowo, kiedy jeden z kontenerów przestaje działać, musi zostać wymieniony.
Nie byłoby prościej, aby takimi działaniami zajmował się jakiś system?
I tu właśnie przychodzi z pomocą Kubernetes!
Kubernetes zapewnia środowisko do uruchamiania systemów rozproszonych o wysokiej niezawodności.
Kubernetes obsługuje skalowanie aplikacji, przełączanie w sytuacjach awaryjnych, różne scenariusze wdrożeń itp.
Przykładowo, Kubernetes w łatwy sposób może zarządzać wdrożeniem nowej wersji oprogramowania zgodnie z metodyką canary deployments.
Kubernetes zapewnia:
Detekcję nowych serwisów i balansowanie ruchu
Kubernetes może udostępnić kontener używając nazwy DNS lub swojego własnego adresu IP.
Jeśli ruch przychodzący do kontenera jest duży, Kubernetes może balansować obciążenie i przekierować ruch sieciowy,
aby zapewnić stabilność całej instalacji.
Zarządzanie obsługą składowania danych
Kubernetes umożliwia automatyczne montowanie systemów składowania danych dowolnego typu —
lokalnych, od dostawców chmurowych i innych.
Automatyczne wdrożenia i wycofywanie zmian
Możesz opisać oczekiwany stan instalacji za pomocą Kubernetesa,
który zajmie się doprowadzeniem w sposób kontrolowany stanu faktycznego do stanu oczekiwanego.
Przykładowo, przy pomocy Kubernetesa możesz zautomatyzować proces tworzenia nowych kontenerów
na potrzeby swojego wdrożenia, usuwania istniejących i przejęcia zasobów przez nowe kontenery.
Automatyczne zarządzanie dostępnymi zasobami
Twoim zadaniem jest dostarczenie klastra maszyn, które Kubernetes może wykorzystać do uruchamiania zadań w kontenerach.
Określasz zapotrzebowanie na moc procesora i pamięć RAM dla każdego z kontenerów.
Kubernetes rozmieszcza kontenery na maszynach w taki sposób, aby jak najlepiej wykorzystać dostarczone zasoby.
Samoczynne naprawianie
Kubernetes restartuje kontenery, które przestały działać, wymienia je na nowe, wymusza wyłączenie kontenerów,
które nie odpowiadają na określone zapytania o stan
i nie rozgłasza powiadomień o ich dostępności tak długo, dopóki nie są gotowe do działania.
Zarządzanie informacjami poufnymi i konfiguracją
Kubernetes pozwala składować i zarządzać informacjami poufnymi, takimi jak hasła, tokeny OAuth czy klucze SSH.
Informacje poufne i zawierające konfigurację aplikacji mogą być dostarczane i zmieniane bez konieczności ponownego budowania obrazu kontenerów
i bez ujawniania poufnych danych w ogólnej konfiguracji oprogramowania.
Czym Kubernetes nie jest
Kubernetes nie jest tradycyjnym, zawierającym wszystko systemem PaaS (Platform as a Service).
Ponieważ Kubernetes działa w warstwie kontenerów, a nie sprzętu, posiada różne funkcjonalności ogólnego zastosowania,
wspólne dla innych rozwiązań PaaS, takie jak: instalacje (deployments), skalowanie i balansowanie ruchu,
umożliwiając użytkownikom integrację rozwiązań służących do logowania, monitoringu i ostrzegania.
Co ważne, Kubernetes nie jest monolitem i domyślnie dostępne rozwiązania są opcjonalne i działają jako wtyczki.
Kubernetes dostarcza elementy, z których może być zbudowana platforma deweloperska,
ale pozostawia użytkownikowi wybór i elastyczność tam, gdzie jest to ważne.
Kubernetes:
Nie ogranicza typów aplikacji, które są obsługiwane. Celem Kubernetesa jest możliwość obsługi bardzo różnorodnego typu zadań,
włączając w to aplikacje bezstanowe (stateless), aplikacje ze stanem (stateful) i ogólne przetwarzanie danych.
Jeśli jakaś aplikacja może działać w kontenerze, będzie doskonale sobie radzić w środowisku Kubernetesa.
Nie oferuje wdrażania aplikacji wprost z kodu źródłowego i nie buduje aplikacji.
Procesy Continuous Integration, Delivery, and Deployment (CI/CD) są zależne od kultury pracy organizacji,
jej preferencji oraz wymagań technicznych.
Nie dostarcza serwisów z warstwy aplikacyjnej, takich jak warstwy pośrednie middleware (np. broker wiadomości),
środowiska analizy danych (np. Spark), bazy danych (np. MySQL),
cache ani klastrowych systemów składowania danych (np. Ceph) jako usług wbudowanych.
Te składniki mogą być uruchamiane na klastrze Kubernetes i udostępniane innym aplikacjom przez przenośne rozwiązania,
takie jak Open Service Broker.
Nie wymusza użycia konkretnych systemów zbierania logów, monitorowania ani ostrzegania.
Niektóre z tych rozwiązań są udostępnione jako przykłady. Dostępne są też mechanizmy do gromadzenia i eksportowania różnych metryk.
Nie dostarcza, ani nie wymusza języka/systemu używanego do konfiguracji (np. Jsonnet).
Udostępnia API typu deklaratywnego, z którego można korzystać za pomocą różnych metod wykorzystujących deklaratywne specyfikacje.
Nie zapewnia, ani nie wykorzystuje żadnego ogólnego systemu do zarządzania konfiguracją,
utrzymaniem i samo-naprawianiem maszyn.
Co więcej, nie jest zwykłym systemem planowania (orchestration). W rzeczywistości, eliminuje konieczność orkiestracji.
Zgodnie z definicją techniczną, orkiestracja to wykonywanie określonego ciągu zadań: najpierw A, potem B i następnie C. Dla kontrastu,
Kubernetes składa się z wielu niezależnych, możliwych do złożenia procesów sterujących,
których zadaniem jest doprowadzenie stanu faktycznego do stanu oczekiwanego. Nie ma znaczenia, w jaki sposób przechodzi się od A do C.
Nie ma konieczności scentralizowanego zarządzania. Dzięki temu otrzymujemy system, który jest potężniejszy,
bardziej odporny i niezawodny i dający więcej możliwości rozbudowy.
🛇 Ta pozycja przekierowuje do projektu lub produktu, który nie jest częścią projektu Kubernetes. Więcej informacji
Klaster może wymagać dodatkowego oprogramowania na każdym węźle; możesz na przykład uruchomić
systemd na węzłach z systemem Linux do monitorowania i zarządzania lokalnymi usługami.
Dodatki (Addons)
Dodatki rozszerzają funkcjonalność Kubernetesa. Oto kilka ważnych przykładów:
Umożliwia zbieranie i przechowywanie logów z kontenerów w centralnym systemie logowania dostępnym na poziomie całego klastra.
Elastyczność architektury
Dzięki elastycznej architekturze Kubernetesa można dostosować sposób
wdrażania i zarządzania poszczególnymi komponentami do konkretnych wymagań - od prostych
klastrów deweloperskich po złożone systemy produkcyjne na dużą skalę.
Szczegółowe informacje o każdym komponencie oraz różnych sposobach konfiguracji
architektury klastra znajdziesz na stronie Architektura klastra.
1.2 - API Kubernetesa
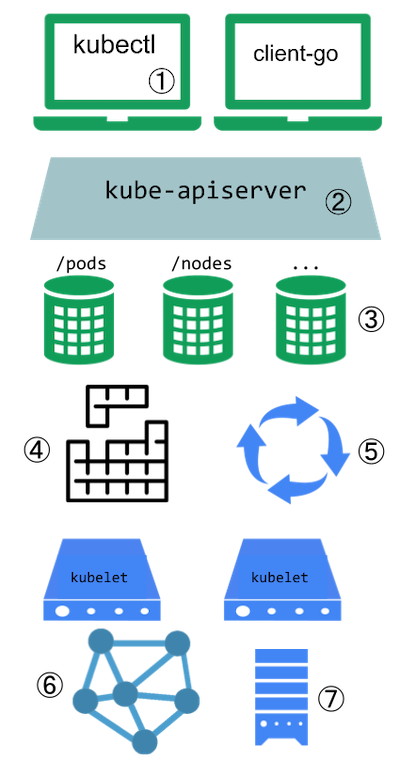
API Kubernetesa służy do odpytywania i zmiany stanu obiektów Kubernetesa. Sercem warstwy sterowania Kubernetesa jest serwer API i udostępniane po HTTP API. Przez ten serwer odbywa się komunikacja pomiędzy użytkownikami, różnymi częściami składowymi klastra oraz komponentami zewnętrznymi.
Sercem warstwy sterowania Kubernetes
jest serwer API. Serwer udostępnia
API poprzez HTTP, umożliwiając wzajemną komunikację pomiędzy użytkownikami, częściami składowymi klastra
i komponentami zewnętrznymi.
API Kubernetesa pozwala na sprawdzanie i zmianę stanu obiektów
(przykładowo: pody, Namespaces, ConfigMaps, Events).
Większość operacji może zostać wykonana poprzez
interfejs linii komend (CLI) kubectl lub inne
programy, takie jak
kubeadm, które używają
API. Możesz też korzystać z API bezpośrednio przez wywołania typu REST.
Jeśli piszesz aplikację używającą API Kubernetesa,
warto rozważyć użycie jednej z bibliotek klienckich.
Specyfikacja OpenAPI
Pełną specyfikację API udokumentowano za pomocą OpenAPI.
Serwer API Kubernetesa udostępnia specyfikację OpenAPI poprzez
ścieżkę /openapi/v2. Aby wybrać format odpowiedzi,
użyj nagłówków żądania zgodnie z tabelą:
Dopuszczalne wartości nagłówka żądania dla zapytań OpenAPI v2
W Kubernetesie zaimplementowany jest alternatywny format serializacji na potrzeby API oparty o
Protobuf, który jest przede wszystkim przeznaczony na potrzeby wewnętrznej komunikacji w klastrze.
Więcej szczegółów znajduje się w dokumencie Kubernetes Protobuf serialization.
oraz w plikach Interface Definition Language (IDL) dla każdego ze schematów
zamieszczonych w pakietach Go, które definiują obiekty API.
OpenAPI V3
STATUS FUNKCJONALNOŚCI:Kubernetes v1.24 [beta]
Kubernetes v1.33 publikuje (na razie w wersji roboczej) własne API zgodnie ze specyfikacją OpenAPI v3.
Ta funkcjonalność jest w wersji beta i jest domyślnie włączona.
Funkcjonalności w wersji beta można wyłączać poprzez
feature gate o nazwie OpenAPIV3
składnika kube-apiserver.
Pod adresem /openapi/v3 można znaleźć listę wszystkich
dostępnych grup/wersji. Zwracane wartości są dostępne tylko w formacie JSON. Grupy/wersje
opisane są następującym schematem:
Względne adresy URL wskazują na niezmieniające się opisy OpenAPI,
aby umożliwić trzymanie cache po stronie klienta. Serwer API zwraca
również odpowiednie nagłówki HTTP dla cache (Expires ustawione na 1 rok wprzód,
Cache-Control jako immutable). Wysłanie zapytania do nieaktualnego URL
spowoduje przekierowanie przez serwer API do wersji najnowszej.
Serwer API Kubernetesa udostępnia specyfikację OpenAPI v3
pod adresem /openapi/v3/apis/<group>/<version>?hash=<hash>,
zgodnie z podziałem na grupy i wersje.
Tabela poniżej podaje dopuszczalne wartości nagłówków żądania.
Dopuszczalne wartości nagłówka żądania dla zapytań OpenAPI v3
Kubernetes przechowuje serializowany stan swoich obiektów w
etcd.
Grupy i wersje API
Aby ułatwić usuwanie poszczególnych pól lub restrukturyzację reprezentacji zasobów, Kubernetes obsługuje
równocześnie wiele wersji API, każde poprzez osobną ścieżkę API,
na przykład: /api/v1 lub /apis/rbac.authorization.k8s.io/v1alpha1.
Rozdział wersji wprowadzony jest na poziomie całego API, a nie na poziomach poszczególnych zasobów lub pól,
aby być pewnym, że API odzwierciedla w sposób przejrzysty i spójny zasoby systemowe
i ich zachowania oraz pozwala na kontrolowany dostęp do tych API, które są w fazie wycofywania
lub fazie eksperymentalnej.
Zasoby API są rozróżniane poprzez przynależność do grupy API, typ zasobu, przestrzeń nazw (namespace,
o ile ma zastosowanie) oraz nazwę. Serwer API może przeprowadzać konwersję między
różnymi wersjami API w sposób niewidoczny dla użytkownika: wszystkie te różne wersje
reprezentują w rzeczywistości ten sam zasób. Serwer API może udostępniać te same dane
poprzez kilka różnych wersji API.
Załóżmy przykładowo, że istnieją dwie wersje v1 i v1beta1 tego samego zasobu.
Obiekt utworzony przez wersję v1beta1 może być odczytany,
zaktualizowany i skasowany zarówno przez wersję
v1beta1, jak i v1, do czasu aż wersja v1beta1 będzie przestarzała i usunięta.
Wtedy możesz dalej korzystać i modyfikować obiekt poprzez wersję v1.
Trwałość API
Z naszego doświadczenia wynika, że każdy system, który odniósł sukces, musi się nieustająco rozwijać w miarę zmieniających się potrzeb.
Dlatego Kubernetes został tak zaprojektowany, aby API mogło się zmieniać i rozrastać.
Projekt Kubernetes dąży do tego, aby nie wprowadzać zmian niezgodnych z istniejącymi aplikacjami klienckimi
i utrzymywać zgodność przez wystarczająco długi czas, aby inne projekty zdążyły się dostosować do zmian.
W ogólności, nowe zasoby i pola definiujące zasoby API są dodawane stosunkowo często.
Usuwanie zasobów lub pól jest regulowane przez
API deprecation policy.
Po osiągnięciu przez API statusu ogólnej dostępności (general availability - GA),
oznaczanej zazwyczaj jako wersja API v1, bardzo zależy nam na utrzymaniu jej zgodności w kolejnych wydaniach.
Kubernetes utrzymuje także zgodność dla wersji beta API tam, gdzie jest to możliwe:
jeśli zdecydowałeś się używać API w wersji beta, możesz z niego korzystać także później,
kiedy dana funkcjonalność osiągnie status stabilnej.
Informacja:
Mimo, że Kubernetes stara się także zachować zgodność dla API w wersji alpha, zdarzają się przypadki,
kiedy nie jest to możliwe. Jeśli korzystasz z API w wersji alfa, przed aktualizacją klastra do nowej wersji
zalecamy sprawdzenie w informacjach o wydaniu, czy nie nastąpiła jakaś zmiana w tej części API.
Punkty dostępowe API (endpoints), typy zasobów i przykłady zamieszczono w
API Reference.
Aby dowiedzieć się, jaki rodzaj zmian można określić jako zgodne i jak zmieniać API, zajrzyj do
API changes.
2 - Architektura klastra
Podstawowe założenia architektury Kubernetesa.
Klaster Kubernetesa składa się z warstwy sterowania oraz zestawu maszyn roboczych, zwanych węzłami, które
uruchamiają konteneryzowane aplikacje. Każdy klaster potrzebuje co najmniej jednego węzła roboczego, aby obsługiwać Pody.
Węzeł roboczy hostuje Pody, które są komponentami workload aplikacji. Warstwa
sterowania zarządza węzłami roboczymi oraz Podami w klastrze. W środowiskach
produkcyjnych, warstwa sterowania zazwyczaj działa na wielu komputerach, a klaster
zazwyczaj działa na wielu węzłach, zapewniając odporność na awarie i wysoką dostępność.
Ten dokument opisuje różne komponenty, które musisz posiadać, aby mieć kompletny i działający klaster Kubernetesa.
Rysunek 1. Komponenty klastra Kubernetesa.
About this architecture
Diagram na Rysunku 1 przedstawia przykładową referencyjną architekturę klastra Kubernetesa.
Rzeczywisty rozkład komponentów może różnić się w zależności od specyficznych konfiguracji klastra i wymagań.
Na schemacie każdy węzeł uruchamia komponent kube-proxy.
Potrzebujesz komponentu sieciowego proxy na każdym węźle, aby
zapewnić, że API Service i
związane z nim zachowania są dostępne w sieci klastra. Niektóre wtyczki
sieciowe jednak dostarczają własne, zewnętrzne implementacje proxy. Kiedy
korzystasz z tego rodzaju wtyczki sieciowej, węzeł nie musi uruchamiać kube-proxy.
Komponenty warstwy sterowania
Komponenty warstwy sterowania podejmują globalne decyzje dotyczące klastra (na
przykład harmonogramowanie), a także wykrywają i reagują na zdarzenia klastra (na
przykład uruchamianie nowego poda gdy nie
zgadza się liczba replik Deploymentu.
Elementy warstwy sterowania mogą być uruchamiane na dowolnej maszynie w klastrze. Jednakże, dla uproszczenia, skrypty
instalacyjne zazwyczaj uruchamiają wszystkie elementy warstwy sterowania na tej samej maszynie i nie uruchamiają kontenerów
użytkownika na tej maszynie. Zobacz Tworzenie klastrów o wysokiej dostępności za pomocą kubeadm
dla przykładowej konfiguracji warstwy sterowania, która działa na wielu maszynach.
kube-apiserver
Serwer API jest składnikiem
warstwy sterowania Kubernetesa, który udostępnia API.
Server API służy jako front-end warstwy sterowania Kubernetesa.
Podstawową implementacją serwera API Kubernetesa jest kube-apiserver.
kube-apiserver został zaprojektowany w taki sposób, aby móc skalować się horyzontalnie — to oznacza, że zwiększa swoją wydajność poprzez dodawanie kolejnych instancji.
Można uruchomić kilka instancji kube-apiserver i rozkładać między nimi ruch od klientów.
etcd
Magazyn typu klucz-wartość (key/value store), zapewniający spójność i wysoką dostępność, używany do przechowywania wszystkich danych o klastrze Kubernetesa.
Jeśli Twój klaster Kubernetesa używa etcd do przechowywania swoich danych, upewnij się, że masz opracowany plan tworzenia
kopii zapasowych tych danych.
Szczegółowe informacje na temat etcd można znaleźć w oficjalnej dokumentacji.
kube-scheduler
Składnik warstwy sterowania, który śledzi tworzenie nowych
podów i przypisuje im węzły,
na których powinny zostać uruchomione.
Przy podejmowaniu decyzji o wyborze węzła brane pod uwagę są wymagania
indywidualne i zbiorcze odnośnie zasobów, ograniczenia wynikające z polityk
sprzętu i oprogramowania, wymagania affinity i anty-affinity, lokalizacja danych,
zależności między zadaniami i wymagania czasowe.
kube-controller-manager
Składnik warstwy sterowania odpowiedzialny za uruchamianie kontrolerów.
Z poziomu podziału logicznego, każdy kontroler jest oddzielnym procesem, ale w celu zmniejszenia złożoności, wszystkie kontrolery są skompilowane do jednego programu binarnego i uruchamiane jako jeden proces.
Istnieje wiele różnych typów kontrolerów. Niektóre z nich to:
Kontroler węzłów (ang. Node controller): Odpowiada za zauważanie i reagowanie, gdy węzły przestają działać.
Kontroler zadania (ang. Job controller): Monitoruje obiekty zadania (Job), które reprezentują jednorazowe zadania, a następnie tworzy Pody, aby wykonały te zadania do końca.
Kontroler EndpointSlice: Uzupełnia obiekty EndpointSlice (aby zapewnić połączenie między Services a Pods).
Kontroler ServiceAccount: Tworzenie domyślnych obiektów ServiceAccount dla nowych przestrzeni nazw.
Powyższa lista nie jest wyczerpującą.
cloud-controller-manager
Element składowy warstwy sterowania Kubernetesa,
który zarządza usługami realizowanymi po stronie chmur obliczeniowych. Cloud controller manager umożliwia
połączenie Twojego klastra z API operatora usług chmurowych i rozdziela składniki operujące na platformie
chmurowej od tych, które dotyczą wyłącznie samego klastra.
Manager 'cloud-controller' uruchamia tylko kontrolery specyficzne dla dostawcy
chmury. Jeśli uruchamiasz Kubernetesa w swojej siedzibie lub w środowisku do
nauki na swoim komputerze osobistym, klaster nie posiada managera 'cloud-controller'.
Podobnie jak kube-controller-manager, cloud-controller-manager łączy kilka logicznie niezależnych
pętli kontrolnych w jedną binarkę, którą uruchamiasz jako pojedynczy proces. Możesz go skalować
horyzontalnie (uruchamiając więcej niż jedną kopię), aby poprawić wydajność lub pomóc w tolerowaniu awarii.
Następujące kontrolery mogą mieć zależności od dostawcy chmury:
Kontroler węzłów (ang. Node controller): Do sprawdzania dostawcy chmury w
celu ustalenia, czy węzeł został usunięty w chmurze po tym, jak przestaje odpowiadać.
Kontroler tras (ang. Route controller): Do konfiguracji tras w podstawowej infrastrukturze chmurowej.
Kontroler usługi (ang. Service controller): Do tworzenia, aktualizowania i usuwania load balancerów dostawcy chmury.
Komponenty węzła
Komponenty węzła działają na każdym węźle, utrzymując działające pody i zapewniając środowisko wykonawcze Kubernetesa.
kubelet
Agent, który działa na każdym węźle klastra. Odpowiada za uruchamianie kontenerów w ramach poda.
kubelet
korzysta z dostarczanych (różnymi metodami) PodSpecs i gwarantuje, że
kontenery opisane przez te PodSpecs są uruchomione i działają poprawnie.
Kubelet nie zarządza kontenerami, które nie zostały utworzone przez Kubernetesa.
kube-proxy (opcjonalne)
kube-proxy to proxy sieciowe, które uruchomione jest na każdym
węźle klastra
i uczestniczy w tworzeniu
serwisu.
kube-proxy
utrzymuje reguły sieciowe na węźle. Dzięki tym regułom
sieci na zewnątrz i wewnątrz klastra mogą komunikować się
z podami.
kube-proxy używa warstwy filtrowania pakietów dostarczanych przez system operacyjny, o ile taka jest dostępna.
W przeciwnym przypadku, kube-proxy samo zajmuje sie przekazywaniem ruchu sieciowego.
Jeśli
używasz wtyczki sieciowej, która samodzielnie
implementuje przekazywanie pakietów dla Usług i zapewnia równoważne działanie
do kube-proxy, to nie musisz uruchamiać kube-proxy na węzłach w swoim klastrze.
Środowisko uruchomieniowe kontenera
Podstawowy komponent umożliwiający efektywne uruchamianie kontenerów w Kubernetesie.
Odpowiada za zarządzanie uruchamianiem i cyklem życia kontenerów w środowisku Kubernetes.
Dodatki (ang. Addons) wykorzystują zasoby Kubernetesa
(DaemonSet, Deployment,
itp.) do wdrażania funkcji klastra. Ponieważ zapewniają one
funkcje na poziomie klastra, zasoby te należą do przestrzeni nazw kube-system.
Wybrane dodatki są opisane poniżej; aby uzyskać rozszerzoną listę
dostępnych dodatków, zobacz Dodatki.
DNS
Podczas gdy inne dodatki nie są ściśle wymagane, wszystkie klastry Kubernetes powinny mieć
DNS klastra, ponieważ wiele elementów na nim polega.
Cluster DNS to serwer DNS, będący uzupełnieniem dla innych serwerów
DNS w Twoim środowisku, który obsługuje rekordy DNS dla usług Kubernetes.
Kontenery uruchamiane przez Kubernetesa automatycznie uwzględniają ten serwer DNS w swoich wyszukiwaniach DNS.
Interfejs Web UI (Dashboard)
Dashboard to uniwersalny interfejs
internetowy dla klastrów Kubernetesa. Umożliwia użytkownikom zarządzanie
i rozwiązywanie problemów z aplikacjami działającymi w klastrze, a także samym klastrem.
Monitorowanie zasobów kontenerów
Monitorowanie Zasobów Kontenera rejestruje ogólne
metryki dotyczące kontenerów w centralnej bazie danych i udostępnia interfejs użytkownika do przeglądania tych danych.
Rejestrowanie na poziomie klastra
Mechanizm logowania na poziomie klastra jest
odpowiedzialny za zapisywanie logów z kontenerów w centralnym magazynie logów z interfejsem do przeszukiwania/przeglądania.
Wtyczki sieciowe
Wtyczki sieciowe
są komponentami oprogramowania, które implementują
specyfikację interfejsu sieciowego kontenera (CNI). Są odpowiedzialne za
przydzielanie adresów IP do podów i umożliwianie im komunikacji między sobą w klastrze.
Warianty architektury
Podczas gdy podstawowe komponenty Kubernetesa pozostają niezmienne, sposób ich
wdrażania i zarządzania może się różnić. Zrozumienie tych wariacji jest kluczowe dla
projektowania i utrzymania klastrów Kubernetesa, które spełniają określone potrzeby operacyjne.
Opcje wdrażania warstwy sterowania
Komponenty warstwy sterowania mogą być wdrażane na kilka sposobów:
Tradycyjna implementacja: : Komponenty warstwy sterowania działają bezpośrednio na
dedykowanych maszynach lub maszynach wirtualnych (VM), często zarządzane jako usługi systemd.
Statyczne Pody: : Komponenty warstwy sterowania są wdrażane jako
statyczne Pody, zarządzane przez kubelet na określonych węzłach.
Jest to powszechne podejście stosowane przez narzędzia takie jak kubeadm.
Samodzielnie hostowane : Warstwa sterowania działa jako Pody
wewnątrz samego klastra Kubernetes, zarządzane
przez Deploymenty i StatefulSety lub inne obiekty Kubernetesa.
Zarządzane usługi Kubernetesa: Dostawcy usług chmurowych zazwyczaj
ukrywają warstwę kontrolną, zarządzając jej elementami w ramach swoich usług.
Rozważania dotyczące umieszczania workloadów
Umiejscowienie workloadów, w tym komponentów warstwy sterowania, może różnić się w
zależności od wielkości klastra, wymagań dotyczących wydajności i polityk operacyjnych:
W mniejszych klastrach lub klastrach deweloperskich, komponenty warstwy sterowania i workloady użytkowników mogą działać na tych samych węzłach.
Większe klastry produkcyjne często dedykują określone węzły dla
komponentów warstwy sterowania, oddzielając je od workloadów użytkowników.
Niektóre organizacje uruchamiają krytyczne dodatki lub narzędzia monitorujące na węzłach warstwy sterowania.
Narzędzia do zarządzania klastrem
Narzędzia takie jak kubeadm, kops i Kubespray oferują różne podejścia do wdrażania i
zarządzania klastrami, z których każde ma własną metodę rozmieszczenia i zarządzania komponentami.
Elastyczność architektury Kubernetesa umożliwia organizacjom dostosowanie ich klastrów do
specyficznych potrzeb, balansując czynniki takie jak złożoność operacyjna, wydajność i narzut na zarządzanie.
Dostosowywanie i rozszerzalność
Architektura Kubernetesa pozwala na szeroką konfigurację:
Niestandardowe schedulery mogą być wdrażane do pracy wraz z domyślnym schedulerem Kubernetesa lub aby całkowicie go zastąpić.
Serwery API mogą być rozszerzane za pomocą CustomResourceDefinitions i agregacji API.
Dostawcy chmury mogą mocno integrować się z Kubernetesem używając cloud-controller-manager.
Elastyczność architektury Kubernetesa umożliwia organizacjom dostosowanie ich klastrów do
specyficznych potrzeb, balansując czynniki takie jak złożoność operacyjna, wydajność i narzut na zarządzanie.
System "pakowania" aplikacji i jej zależności w spójne środowisko uruchomieniowe.
Ta strona omawia kontenery i obrazy kontenerów, a także ich zastosowanie w utrzymaniu systemów i tworzeniu rozwiązań.
Słowo kontener (ang. container) jest wieloznacznym pojęciem. Zawsze, gdy go używasz, sprawdź, czy Twoi odbiorcy stosują tę samą definicję.
Każdy uruchamiany kontener jest powtarzalny;
standaryzacja wynikająca z uwzględnienia zależności oznacza, że uzyskujesz
to samo zachowanie, gdziekolwiek go uruchomisz.
Kontenery oddzielają aplikacje od infrastruktury hosta. To ułatwia
wdrażanie w różnych środowiskach chmurowych lub systemach operacyjnych.
Każdy węzeł w klastrze
Kubernetesa uruchamia kontenery, które tworzą
Pody przypisane do tego węzła. Kontenery należące do jednego
Poda są uruchamiane razem na tym samym węźle w ramach wspólnego harmonogramu.
Obrazy kontenerów
Obraz kontenera to gotowy do
uruchomienia pakiet oprogramowania zawierający wszystko, co jest potrzebne do
uruchomienia aplikacji: kod i wszelkie wymagane środowiska uruchomieniowe,
biblioteki aplikacji i systemowe, oraz wartości domyślne dla wszelkich niezbędnych ustawień.
Kontenery są przeznaczone do bycia bezstanowymi i
niezmiennymi:
nie powinieneś zmieniać kodu kontenera,
który już działa. Jeśli masz aplikację konteneryzowaną i
chcesz dokonać zmian, właściwym procesem jest
zbudowanie nowego obrazu zawierającego zmiany, a następnie
odtworzenie kontenera w celu uruchomienia go z zaktualizowanego obrazu.
Środowiska uruchomieniowe kontenerów
Podstawowy komponent umożliwiający efektywne uruchamianie kontenerów w Kubernetesie.
Odpowiada za zarządzanie uruchamianiem i cyklem życia kontenerów w środowisku Kubernetes.
Zazwyczaj możesz pozwolić swojemu klastrowi na wybranie domyślnego środowiska
uruchomieniowego kontenera dla Poda. Jeśli musisz używać więcej niż jednego
środowiska uruchomieniowego kontenera w swoim klastrze, możesz określić
RuntimeClass dla Poda, aby upewnić się, że
Kubernetes uruchamia te kontenery przy użyciu konkretnego środowiska uruchomieniowego kontenera.
Możesz również użyć RuntimeClass, aby uruchamiać różne Pody z tym
samym środowiskiem uruchomieniowym kontenera, ale z różnymi ustawieniami.
4 - Workload
Poznaj Pody – podstawowy element obliczeniowy w Kubernetes – oraz mechanizmy ułatwiające ich wdrażanie.
Workload to ogólne określenie aplikacji działającej na Kubernetesie. Niezależnie
od tego, czy Twój workload jest pojedynczym komponentem, czy kilkoma
współpracującymi ze sobą, na Kubernetes uruchamiasz go wewnątrz zestawu
podów. Pod reprezentuje zestaw uruchomionych
kontenerów na Twoim klastrze.
Pody mają zdefiniowany cykl życia. Na
przykład, gdy Pod działa w twoim klastrze, krytyczna awaria na
węźle, na którym ten Pod działa, oznacza, że wszystkie Pody na tym węźle
przestają działać. Kubernetes traktuje ten typ awarii jako ostateczny: przywrócenie działania
wymaga utworzenia nowego Poda, nawet jeśli węzeł później zostanie przywrócony do pełnej sprawności.
Jednak, aby znacznie ułatwić sobie życie, nie musisz zarządzać każdym
Podem bezpośrednio. Zamiast tego, możesz użyć obiektów dedykowanych do obsługi workload-ów,
które zarządzają zestawem Podów w Twoim imieniu. Te zasoby konfigurują
kontrolery, które
zapewniają, że odpowiednia liczba Podów działa, zgodnie z tym, co zdefiniowałeś.
Kubernetes udostępnia kilka wbudowanych typów obiektów przeznaczonych do obsługi workload-ów:
Deployment i
ReplicaSet (zastępując przestarzały zasób
ReplicationController). Deployment
jest odpowiedni do zarządzania bezstanowym workloadem aplikacji w
klastrze, gdzie każdy Pod w Deployment jest wymienny i może być zastąpiony, jeśli to konieczne.
StatefulSet pozwala na
uruchomienie jednego lub więcej powiązanych Podów, które przechowują stan i potrafią go
odtwarzać. Na przykład, jeśli Twój workload zapisuje dane w sposób trwały, możesz
uruchomić StatefulSet, który wiąże każdy Pod z PersistentVolume.
Twój kod, działający w ramach Podów dla tego StatefulSet, może
replikować dane do innych Podów w tym samym StatefulSet, aby poprawić ogólną odporność na awarie.
DaemonSet definiuje Pody,
które zapewniają funkcje lokalne dla węzłów. Za każdym razem, gdy dodajesz węzeł do
swojego klastra, który pasuje do specyfikacji w DaemonSet, warstwa sterowania zleca uruchomienie
Poda dla tego DaemonSet na nowym węźle. Każdy Pod w DaemonSet
wykonuje zadanie podobne do demona systemowego na klasycznym serwerze Unix / POSIX.
DaemonSet może być fundamentalny dla działania twojego klastra, na przykład jako
wtyczka do uruchamiania infrastuktury sieciowej klastra,
może pomóc w
zarządzaniu węzłem, lub może zapewniać opcjonalne funkcje, które ulepszają platformę kontenerową.
Job i
CronJob oferują różne sposoby
definiowania zadań, które uruchamiają się do zakończenia, a następnie
zatrzymują. Możesz użyć Job,
aby zdefiniować zadanie, które uruchamia się do zakończenia, tylko
raz. Możesz użyć CronJob,
aby uruchomić to samo zadanie (Job) wielokrotnie według harmonogramu.
W szerszym ekosystemie Kubernetesa można znaleźć definicje zadań od firm trzecich, które
zapewniają dodatkowe zachowania. Korzystając z Custom Resource Definition,
można dodać definicję zadania od firmy
trzeciej, jeśli chcesz uzyskać określone działanie, które nie jest częścią podstawowej wersji
Kubernetesa. Na przykład, jeśli chcesz uruchomić grupę Podów dla swojej aplikacji, ale
zatrzymać pracę, jeśli wszystkie Pody nie są dostępne (może dla jakiegoś zadania
wysokoprzepustowego rozproszonego), to można zaimplementować lub zainstalować rozszerzenie, które oferuje tę funkcję.
Co dalej?
Oprócz przeczytania informacji o każdym rodzaju API do zarządzania workloadami,
możesz dowiedzieć się, jak wykonywać konkretne zadania:
Gdy Twoja aplikacja jest uruchomiona, możesz chcieć udostępnić ją w internecie jako
Service lub, tylko dla
aplikacji webowych, używając Ingress.
4.1 - Pod
Pod jest najmniejszą jednostką obliczeniową, którą można utworzyć i zarządzać nią w Kubernetesie.
Pod (w języku angielskim: jak w odniesieniu do grupy wielorybów lub strąka grochu) to grupa jednego lub więcej
kontenerów, z współdzielonymi zasobami pamięci i sieci, oraz specyfikacją
dotyczącą sposobu uruchamiania kontenerów. Wszystkie komponenty Poda są uruchamiane razem, współdzielą ten sam kontekst i są
planowane do uruchomienia na tym samym węźle. Pod modeluje specyficznego dla aplikacji "logicznego hosta": zawiera jeden lub więcej
kontenerów aplikacji, które są stosunkowo ściśle ze sobą powiązane. W kontekstach niechmurowych, aplikacje
wykonane na tej samej maszynie fizycznej lub wirtualnej są analogiczne do aplikacji chmurowych wykonanych na tym samym logicznym hoście.
Oprócz kontenerów aplikacyjnych, Pod może zawierać
kontenery inicjalizujące uruchamiane
podczas startu Pod. Możesz również
wstrzyknąć kontenery efemeryczne
do debugowania działającego Poda.
Wspólny kontekst Poda to zestaw przestrzeni nazw Linux, cgroups i potencjalnie innych aspektów izolacji - te
same elementy, które izolują kontener (ang. container).
W obrębie kontekstu Poda, poszczególne aplikacje mogą mieć dodatkowo zastosowane dalsze sub-izolacje.
Pod jest podobny do zestawu kontenerów z współdzielonymi przestrzeniami nazw i współdzielonymi woluminami systemu plików.
Pody w klastrze Kubernetesa są używane na dwa główne sposoby:
Pody, które uruchamiają pojedynczy kontener. Model
"jeden-kontener-na-Poda" jest najczęstszym przypadkiem użycia; w tym przypadku
możesz myśleć o Podzie jako o obudowie wokół pojedynczego kontenera; Kubernetes
zarządza Podami, zamiast zarządzać kontenerami bezpośrednio.
Pody, które uruchamiają wiele kontenerów, które muszą współdziałać.
Pod może zawierać aplikację składającą się z
wielu współlokalizowanych kontenerów,
które są ściśle powiązane i muszą współdzielić
zasoby. Te współlokalizowane kontenery tworzą jedną spójną jednostkę.
Grupowanie wielu współlokalizowanych i współzarządzanych kontenerów w jednym
Podzie jest stosunkowo zaawansowanym przypadkiem użycia. Ten wzorzec powinieneś używać
tylko w określonych przypadkach, gdy twoje kontenery są ściśle powiązane.
Nie musisz uruchamiać wielu kontenerów, aby zapewnić replikację
(dla odporności lub pojemności); jeśli potrzebujesz wielu replik,
zobacz zarządzanie workloadami.
Używanie Podów
Poniżej znajduje się przykład Poda, który składa się z kontenera uruchamiającego obraz nginx:1.14.2.
Pody zazwyczaj nie są tworzone bezpośrednio tylko przy użyciu
specjalnych zadań (workload). Zobacz Praca z Podami aby
uzyskać więcej informacji na temat tego, jak Pody są używane z zasobami workload.
Zasoby workload do zarządzania podami
Zazwyczaj nie musisz tworzyć Podów bezpośrednio, nawet pojedynczych Podów. Zamiast tego,
twórz je używając zasobów workload, takich jak Deployment
lub Job. Jeśli Twoje Pody muszą
śledzić stan, rozważ użycie zasobu StatefulSet.
Każdy Pod ma na celu uruchomienie pojedynczej instancji danej aplikacji. Jeśli
chcesz skalować swoją aplikację horyzontalnie (aby zapewnić więcej zasobów ogółem
poprzez uruchomienie większej liczby instancji), powinieneś użyć wielu Podów,
jednego dla każdej instancji. W Kubernetesie, operację tę zazwyczaj określa się
mianem replikacji. Replikowane Pody są zazwyczaj tworzone i zarządzane jako grupa
przez zasób workload i jego kontroler.
Zobacz Pody i kontrolery, aby uzyskać więcej
informacji na temat tego, jak Kubernetes wykorzystuje zasoby workload oraz ich kontrolery
do implementacji skalowania aplikacji i automatycznego naprawiania.
Pody natywnie zapewniają dwa rodzaje zasobów współdzielonych dla ich
składowych kontenerów: sieć i przechowywanie.
Praca z Podami
Rzadko będziesz tworzyć indywidualne Pody bezpośrednio w Kubernetesie - nawet
pojedyncze Pody. Dzieje się tak, ponieważ Pody są zaprojektowane jako stosunkowo efemeryczne,
jednorazowe obiekty. Kiedy Pod zostaje utworzony (bezpośrednio przez Ciebie lub pośrednio przez
kontroller), nowy Pod jest
planowany do uruchomienia na węźle w
Twoim klastrze. Pod pozostaje na tym węźle, dopóki nie zakończy wykonywania, obiekt Poda
nie zostanie usunięty, Pod nie zostanie usunięty z powodu braku zasobów lub węzeł ulegnie awarii.
Informacja:
Restartowanie kontenera w Podzie nie powinno być mylone z
restartowaniem Poda. Pod nie jest procesem, ale środowiskiem do
uruchamiania kontenera(-ów). Pod trwa, dopóki nie zostanie usunięty.
Nazwa Poda musi być prawidłową wartością
poddomeny DNS, ale może to
powodować nieoczekiwane skutki w odniesieniu do jego nazwy hosta. Dla najlepszej kompatybilności,
nazwa powinna spełniać bardziej restrykcyjne zasady dla
etykiety DNS.
System operacyjny Poda
STATUS FUNKCJONALNOŚCI:Kubernetes v1.25 [stable]
Powinieneś ustawić pole .spec.os.name na windows lub linux, aby wskazać system
operacyjny, na którym chcesz uruchomić swojego Poda. Są to jedyne obsługiwane systemy
operacyjne przez Kubernetesa w chwili obecnej. W przyszłości lista ta może zostać rozszerzona.
W Kubernetesie v1.33, wartość .spec.os.name nie wpływa na to, w jaki
sposób kube-scheduler
wybiera węzeł do uruchomienia Poda. W każdym klastrze, w którym istnieje więcej niż jeden
system operacyjny dla działających węzłów, powinieneś poprawnie ustawić etykietę
kubernetes.io/os na każdym węźle
i zdefiniować Pody z nodeSelector opartym na etykiecie systemu operacyjnego.
Kube-scheduler przypisuje Pody do węzłów na podstawie określonych kryteriów, ale nie zawsze
gwarantuje wybór węzła z właściwym systemem operacyjnym dla uruchamianych kontenerów.
Standardy bezpieczeństwa Pod również używają tego
pola, aby uniknąć wymuszania polityk, które nie mają zastosowania dla danego systemu operacyjnego.
Pody i kontrolery
Możesz użyć zasobów workload do tworzenia i zarządzania wieloma Podami. Kontroler
dla zasobu obsługuje replikację, wdrażanie oraz automatyczne naprawianie
w przypadku awarii Poda. Na przykład, jeśli węzeł ulegnie
awarii, kontroler zauważa, że Pody na tym węźle przestały działać i
tworzy zastępczego Poda. Scheduler umieszcza zastępczego Poda na zdrowym węźle.
Oto kilka przykładów zasobów workload, które zarządzają Podami:
StatefulSet - komponent Kubernetesa służący do zarządzania aplikacjami stateful. StatefulSet zapewnia zachowanie kolejności i spójności danych w ramach aplikacji, co jest kluczowe dla usług wymagających takiego funkcjonowania. StatefulSet śledzi, które identyfikatory Podów są skojarzone z określonymi zasobami pamięci masowej i w jakiej kolejności powinny być tworzone oraz usuwane.
Kontrolery zasobów workload
tworzą Pody z szablonu poda i zarządzają tymi Podami w Twoim imieniu.
PodTemplates to specyfikacje do tworzenia Podów, które są
uwzględniane w zasobach workload, takich jak Deployments,
Jobs
i DaemonSets.
Każdy kontroler dla zasobu workload używa PodTemplate wewnątrz obiektu
workload do tworzenia rzeczywistych Podów. PodTemplate jest częścią pożądanego
stanu dowolnego zasobu workload, którego użyłeś do uruchomienia swojej aplikacji.
Gdy tworzysz Pod, możesz uwzględnić
zmienne środowiskowe w
szablonie Poda dla kontenerów, które działają w Podzie.
Poniższy przykład to manifest dla prostego zadania (Job) z szablonem (template), który
uruchamia jeden kontener. Kontener w tym Podzie wyświetla komunikat, a następnie się zatrzymuje.
apiVersion:batch/v1kind:Jobmetadata:name:hellospec:template:# This is the pod templatespec:containers:- name:helloimage:busybox:1.28command:['sh','-c','echo "Hello, Kubernetes!" && sleep 3600']restartPolicy:OnFailure# The pod template ends here
Modyfikacja szablonu poda lub przejście na nowy szablon poda nie ma bezpośredniego
wpływu na już istniejące Pody. Jeśli zmienisz szablon poda dla zasobu workload, ten zasób
musi utworzyć nowe, zamienne Pody, które korzystają ze zaktualizowanego szablonu.
Na przykład kontroler StatefulSet zapewnia, że uruchomione Pody odpowiadają bieżącemu
szablonowi Poda dla każdego obiektu StatefulSet. Jeśli edytujesz StatefulSet, aby zmienić jego szablon,
StatefulSet zaczyna tworzyć nowe Pody na podstawie zaktualizowanego szablonu.
Ostatecznie, wszystkie stare Pody zostają zastąpione nowymi Podami, a aktualizacja jest zakończona.
Każdy zasób workload implementuje własne zasady dotyczące obsługi zmian w szablonie Pod. Jeśli
chcesz dowiedzieć się więcej o StatefulSet, zapoznaj się z
strategią aktualizacji w samouczku podstawy StatefulSet.
Na poziomie węzłów kubelet
nie kontroluje bezpośrednio szczegółów dotyczących
szablonów Podów ani ich aktualizacji – są one zarządzane na wyższym
poziomie abstrakcji. Taka separacja upraszcza działanie systemu i
pozwala na rozszerzanie funkcjonalności klastra bez ingerencji w istniejący kod.
Aktualizacja i wymiana Poda
Jak wspomniano w poprzedniej sekcji, gdy szablon Poda dla zasobu
workload zostaje zmieniony, kontroler tworzy nowe Pody na podstawie
zaktualizowanego szablonu zamiast aktualizować lub łatać istniejące Pody.
Kubernetes nie uniemożliwia bezpośredniego zarządzania Podami.
Możliwe jest aktualizowanie niektórych pól działającego Poda, na
miejscu. Jednak operacje aktualizacji Poda, takie jak
patch, oraz
replace
mają pewne ograniczenia:
Większość metadanych o Podzie jest niezmienna. Na przykład, nie
można zmienić pól namespace, name, uid ani creationTimestamp.
Pole generation jest unikatowe. Zostanie automatycznie
ustawione przez system w taki sposób, że nowe pody będą miały ustawioną
wartość na 1, a każda aktualizacja pól w specyfikacji poda zwiększy
generation o 1. Jeśli funkcja alfa PodObservedGenerationTracking
jest włączona, status.observedGeneration poda będzie odzwierciedlał metadata.generation
poda w momencie, gdy status poda jest raportowany.
Jeśli parametr metadata.deletionTimestamp jest
ustawiony, nie można dodać nowego wpisu do listy metadata.finalizers.
Aktualizacje Podów nie mogą zmieniać pól innych niż
spec.containers[*].image, spec.initContainers[*].image, spec.activeDeadlineSeconds lub spec.tolerations.
Dla spec.tolerations można jedynie dodawać nowe wpisy.
Podczas aktualizacji pola
spec.activeDeadlineSeconds dozwolone są dwa typy aktualizacji:
ustawienie nieprzypisanego pola na liczbę dodatnią;
aktualizacja pola z liczby
dodatniej do mniejszej, nieujemnej liczby.
Podzasoby Poda
Powyższe zasady aktualizacji dotyczą standardowych zmian w Podach, jednak niektóre pola Poda mogą być aktualizowane za pomocą podzasobów.
Zmiana rozmiaru: Podzasób resize umożliwia aktualizację zasobów kontenera (spec.containers [*].resources). Szczegółowe informacje znajdują się w sekcji Zmiana rozmiaru zasobów kontenera.
Status: Podzasób status umożliwia aktualizację statusu poda. Zazwyczaj
jest to używane tylko przez Kubelet i kontrolery systemowe.
Przypisanie Poda do węzła: Podzasób binding umożliwia ustawienie spec.nodeName poda za pomocą żądania typu
Binding. Zazwyczaj jest to używane tylko przez kube-scheduler.
Udostępnianie zasobów i komunikacja
Pody umożliwiają udostępnianie danych i
komunikację pomiędzy swoimi składowymi kontenerami.
Pamięć masowa w Podach
Pod może określić zestaw współdzielonych zasobów pamięci masowej
(woluminów). Wszystkie
kontenery w Podzie mają dostęp do tych woluminów, co umożliwia im
współdzielenie danych. Woluminy pozwalają również na utrzymanie danych w Podzie,
nawet jeśli jeden z jego kontenerów wymaga ponownego uruchomienia. Zobacz
sekcję Storage, aby dowiedzieć się więcej o
tym, jak Kubernetes implementuje współdzieloną pamięć masową i udostępnia ją Podom.
Sieci Poda
Każdy Pod ma przypisany unikalny adres IP dla każdej rodziny adresów. Każdy kontener
w Podzie dzieli przestrzeń nazw sieci, w tym adres IP i porty
sieciowe. Wewnątrz Poda (i tylko wtedy) kontenery, które należą do Poda
mogą komunikować się ze sobą za pomocą localhost. Kiedy kontenery w Podzie
komunikują się z jednostkami poza Podem, muszą koordynować sposób
korzystania ze wspólnych zasobów sieciowych (takich jak porty). W ramach Poda,
kontenery dzielą adres IP i przestrzeń portów, i mogą znaleźć się nawzajem za
pośrednictwem localhost. Kontenery w Podzie mogą również komunikować się
między sobą za pomocą standardowych komunikatów międzyprocesowych, takich
jak semafory SystemV lub współdzielona pamięć POSIX. Kontenery w różnych
Podach mają różne adresy IP i nie mogą komunikować się poprzez IPC na poziomie systemu
operacyjnego bez specjalnej konfiguracji. Kontenery, które chcą
nawiązać interakcję z kontenerem działającym w innym Podzie, mogą używać sieci IP do komunikacji.
Kontenery w ramach Pod mają tę samą nazwę hosta systemowego, co
skonfigurowane name dla Pod. Więcej na ten temat znajduje się w sekcji
sieci.
Ustawienia zabezpieczeń Poda
Aby ustawić ograniczenia bezpieczeństwa na Podach i kontenerach, używasz
pola securityContext w specyfikacji Poda. To pole daje Ci szczegółową
kontrolę nad tym, co Pody lub poszczególne kontenery mogą robić. Na przykład:
Usunąć specyficzne uprawnienia Linuxa, aby uniknąć podatności CVE.
Wymusić, aby wszystkie procesy w Podzie były uruchamiane jako użytkownik
nie-root lub jako określony ID użytkownika lub grupy.
Ustawić konkretny profil seccomp.
Ustawić opcje bezpieczeństwa systemu Windows, takie jak to, czy kontenery działają jako HostProcess.
Uwaga:
Możesz również użyć securityContext dla Poda, aby włączyć
tryb uprzywilejowany w
kontenerach Linux. Tryb uprzywilejowany nadpisuje wiele innych ustawień
bezpieczeństwa w securityContext. Unikaj używania tego ustawienia, chyba że nie
możesz przyznać równoważnych uprawnień, korzystając z innych pól w securityContext. W Kubernetesie
1.26 i nowszych, możesz uruchamiać kontenery Windows w podobnie
uprzywilejowanym trybie, ustawiając flagę windowsOptions.hostProcess w kontekście
bezpieczeństwa w specyfikacji Poda. Aby uzyskać szczegóły i instrukcje, zobacz
Utwórz Pod HostProcess w Windows.
Statyczne Pody są zarządzane bezpośrednio przez demona kubelet na
określonym węźle, bez nadzoru przez serwer API.
Podczas gdy większość Podów jest zarządzana przez warstwę
sterowania (na przykład przez
Deployment), w przypadku statycznych Podów to kubelet
bezpośrednio nadzoruje każdy statyczny Pod (i restartuje go, jeśli ulegnie awarii).
Statyczne Pody są zawsze powiązane z jednym komponentem Kubelet na konkretnym węźle.
Głównym zastosowaniem statycznych Podów jest uruchamianie samodzielnie hostowanej warstwy sterowania: innymi słowy, użycie
kubeleta do nadzorowania poszczególnych komponentów warstwy sterowania.
Kubelet automatycznie próbuje utworzyć Pod lustrzany
na serwerze API Kubernetesa dla każdego
statycznego Poda. Oznacza to, że Pody działające na węźle są widoczne na serwerze
API, ale nie mogą być z niego kontrolowane. Więcej informacji znajdziesz w
przewodniku Tworzenie statycznych Podów.
Pody są zaprojektowane do obsługi wielu współpracujących procesów (jako
kontenery), które tworzą spójną jednostkę usługi. Kontenery w Podzie są
automatycznie współlokowane i współharmonogramowane na tej samej fizycznej
lub wirtualnej maszynie w klastrze. Kontenery mogą współdzielić zasoby i
zależności, komunikować się ze sobą oraz koordynować, kiedy i jak są zakończane.
Pody w klastrze Kubernetesa są używane na dwa główne sposoby:
Pody, które uruchamiają pojedynczy kontener. Model
"jeden-kontener-na-Poda" jest najczęstszym przypadkiem użycia; w tym przypadku
możesz myśleć o Podzie jako o obudowie wokół pojedynczego kontenera; Kubernetes
zarządza Podami, zamiast zarządzać kontenerami bezpośrednio.
Pody, które uruchamiają wiele kontenerów, które muszą współpracować.
Pod może zawierać aplikację składającą się z
wielu współlokalizowanych kontenerów, które są ściśle
powiązane i muszą współdzielić zasoby. Te współlokalizowane
kontenery tworzą jedną spójną jednostkę usługi - na przykład,
jeden kontener udostępniający dane przechowywane we
współdzielonym wolumenie publicznym, podczas gdy osobny
kontener sidecar odświeża
lub aktualizuje te pliki. Pod łączy te kontenery,
zasoby pamięci, oraz efemeryczną tożsamość sieciową razem jako jedną jednostkę.
Na przykład, możesz mieć kontener, który działa jako serwer webowy dla
plików we współdzielonym wolumenie oraz oddzielny
kontener pomocniczy (ang. sidecar container), który aktualizuje
te pliki z zewnętrznego źródła, jak pokazano na poniższym diagramie:
Niektóre Pody mają kontenery inicjujące
oraz kontenery aplikacji. Domyślnie,
kontenery inicjujące uruchamiają się i kończą przed startem kontenerów aplikacji.
Możesz również mieć kontenery pomocnicze,
które świadczą usługi pomocnicze dla głównej aplikacji w Podzie.
STATUS FUNKCJONALNOŚCI:Kubernetes v1.33 [stable] (enabled by default: true)
Domyślnie włączona bramka funkcji SidecarContainersfeature gate pozwala na określenie
restartPolicy: Always dla kontenerów inicjalizacyjnych. Ustawienie
polityki restartu Always zapewnia, że kontenery, dla których ją ustawisz, są
traktowane jako sidecar i są utrzymywane w działaniu przez cały czas życia
Poda. Kontenery, które określisz jako kontenery sidecar, uruchamiają się przed
główną aplikacją w Podzie i pozostają uruchomione do momentu, gdy Pod zostanie zamknięty.
Kontenerowe sondy (ang. Container probes)
Sonda (ang. probe) to diagnostyka wykonywana okresowo przez kubelet na
kontenerze. Aby przeprowadzić diagnostykę, kubelet może wywoływać różne akcje:
ExecAction (wykonywane za pomocą środowiska uruchomieniowego kontenera)
TCPSocketAction (sprawdzane bezpośrednio przez kubelet)
HTTPGetAction (sprawdzane bezpośrednio przez kubelet)
Możesz przeczytać więcej o sondach
w dokumentacji cyklu życia Poda.
Aby zrozumieć kontekst, dlaczego Kubernetes opakowuje wspólne API Poda
w inne zasoby (takie jak StatefulSets
lub Deployments),
możesz przeczytać o wcześniejszych rozwiązaniach, w tym:
Kubernetes udostępnia kilka wbudowanych interfejsów API do deklaratywnego
zarządzania Twoim
workloadem oraz jego komponentami.
Twoje aplikacje działają jako kontenery wewnątrz
Podów; jednakże zarządzanie pojedynczymi Podami wiąże się z
dużym wysiłkiem. Na przykład, jeśli jeden Pod ulegnie awarii, prawdopodobnie
będziesz chciał uruchomić nowy Pod, aby go zastąpić. Kubernetes może to zrobić za Ciebie.
Używasz API Kubernetesa aby utworzyć obiekt
zadania (workload), który reprezentuje wyższy poziom abstrakcji niż
Pod, a następnie warstwa sterowania
Kubernetesa automatycznie zarządza obiektami Pod w Twoim
imieniu, na podstawie specyfikacji zdefiniowanego przez Ciebie obiektu tego workloadu.
Wbudowane interfejsy API do zarządzania workloadami to:
Deployment (oraz pośrednio
ReplicaSet), to najczęstszy
sposób uruchamiania aplikacji w klastrze. Deployment jest odpowiedni do
zarządzania aplikacją bezstanową w klastrze, gdzie każdy Pod w Deployment jest wymienny i może
być zastąpiony w razie potrzeby. (Deploymenty zastępują przestarzałe
ReplicationController API).
StatefulSet pozwala
na zarządzanie jednym lub wieloma Podami – wszystkie uruchamiają ten sam
kod aplikacji – gdzie Pody opierają się na posiadaniu unikalnej tożsamości.
Jest to inne niż w przypadku Deployment, gdzie oczekuje się, że Pody są
wymienne. Najczęstszym zastosowaniem StatefulSet jest możliwość powiązania
jego Podów z ich trwałą pamięcią masową. Na przykład, można uruchomić
StatefulSet, który kojarzy każdy Pod z PersistentVolume.
Jeśli jeden z Podów w StatefulSet ulegnie awarii,
Kubernetes tworzy zastępczy Pod, który jest połączony z tym samym PersistentVolume.
DaemonSet definiuje Pody,
które zapewniają funkcje lokalne dla określonego
węzła; na przykład sterownik, który umożliwia kontenerom na tym
węźle dostęp do systemu przechowywania danych. DaemonSet jest wykorzystywany w
sytuacjach, gdy sterownik lub inna usługa na poziomie węzła musi działać na
konkretnym węźle. Każdy Pod w DaemonSet pełni rolę podobną do demona systemowego na
klasycznym serwerze Unix / POSIX. DaemonSet może być kluczowy dla działania twojego
klastra, na przykład jako wtyczka, która pozwala temu węzłowi uzyskać dostęp do
sieci klastrowej,
może pomóc w zarządzaniu węzłem albo
zapewnia mniej istotne funkcje, które wzbogacają używaną platformę kontenerową. Możesz uruchamiać
DaemonSety (i ich pody) na każdym węźle w twoim klastrze, lub tylko
na podzbiorze (na przykład instalując sterownik GPU tylko na węzłach, które mają zainstalowany GPU).
Możesz użyć Job i/lub
CronJob do zdefiniowania zadań, które
działają do momentu ukończenia, a następnie się zatrzymują. Job reprezentuje
jednorazowe zadanie, podczas gdy każdy CronJob powtarza się zgodnie z harmonogramem.
Inne tematy w tej sekcji:
5 - Usługi, równoważenie obciążenia i sieci w Kubernetesie
Pojęcia i zasoby związane z siecią w Kubernetesie.
Model sieciowy Kubernetesa
Model sieci Kubernetesa składa się z kilku części:
Każdy pod
otrzymuje swój własny unikalny adres IP w całym klastrze.
Pod ma swoją własną, prywatną przestrzeń nazw sieci, która jest
współdzielona przez wszystkie kontenery w ramach tego
poda. Procesy działające w różnych kontenerach w tym samym
podzie mogą komunikować się ze sobą za pośrednictwem localhost.
Sieć podów (znana również jako sieć klastra) obsługuje komunikację
między podami. Zapewnia, że (z zastrzeżeniem celowego segmentowania sieci):
Wszystkie pody mogą komunikować się ze wszystkimi innymi podami,
niezależnie od tego, czy znajdują się na tym samym
węźle, czy na różnych węzłach. Pody mogą
komunikować się ze sobą bezpośrednio, bez użycia proxy ani translacji adresów (NAT).
W systemie Windows ta reguła nie dotyczy podów z siecią hosta.
Agenci na węźle (takie jak demony systemowe czy
kubelet) mogą komunikować się ze wszystkimi podami na tym węźle.
Obiekt API Service
pozwala na udostępnienie stabilnego (długoterminowego) adresu IP lub nazwy
hosta dla usługi zrealizowanej przez jeden lub więcej backendowych podów, gdzie
poszczególne pody składające się na usługę mogą zmieniać się w czasie.
Kubernetes automatycznie zarządza obiektami
EndpointSlice aby
dostarczać informacje o Podach obsługujących daną usługę.
Implementacja proxy serwisu monitoruje zestaw obiektów Service i EndpointSlice,
a także konfiguruje warstwę danych w celu
kierowania ruchu serwisowego do jego backendów, używając API systemu
operacyjnego lub dostawcy chmury do przechwytywania lub przepisania pakietów.
Obiekt API Gateway
(lub jego poprzednik, Ingress
) umożliwia udostępnienie usług klientom znajdującym się poza klastrem.
Prostszy, ale mniej konfigurowalny mechanizm dostępu do klastra (Ingress) jest
dostępny za pośrednictwem API usług (Service) z wykorzystaniem opcji
type: LoadBalancer, pod warunkiem
korzystania z obsługiwanego dostawcy chmury (Cloud Provider).
NetworkPolicy
to wbudowane API Kubernetesa, które pozwala na
kontrolowanie ruchu pomiędzy podami, lub pomiędzy podami a światem zewnętrznym.
W starszych systemach kontenerowych nie było automatycznej łączności pomiędzy
kontenerami na różnych hostach, więc często konieczne było jawne
tworzenie połączeń między kontenerami lub mapowanie portów
kontenerów na porty hostów, aby były osiągalne przez kontenery na
innych hostach. W Kubernetesie nie jest to potrzebne; model Kubernetesa
polega na tym, że pody mogą być traktowane podobnie jak maszyny
wirtualne lub fizyczne hosty z perspektyw alokacji portów, nazewnictwa,
wykrywania usług, równoważenia obciążenia, konfiguracji aplikacji i migracji.
Tylko kilka części tego modelu jest implementowanych
przez Kubernetesa samodzielnie. Dla pozostałych części
Kubernetes definiuje API, ale odpowiadającą funkcjonalność
zapewniają zewnętrzne komponenty, z których niektóre są opcjonalne:
Sama sieć podów jest zarządzana przez
implementację sieci podów.
W systemie Linux, większość środowisk
uruchomieniowych kontenerów używa Container Networking Interface (CNI)
do interakcji z implementacją sieci
podów, dlatego te implementacje często nazywane są wtyczkami CNI.
Kubernetes dostarcza domyślną implementację proxy usług,
nazywaną kube-proxy, ale
niektóre implementacje sieciowe poda używają zamiast tego własnego
proxy usług, które jest ściślej zintegrowane z resztą implementacji.
NetworkPolicy jest zazwyczaj również implementowane przez
implementację sieci poda. (Niektóre prostsze implementacje sieci poda nie
implementują NetworkPolicy, lub administrator może zdecydować się na
skonfigurowanie sieci poda bez wsparcia dla NetworkPolicy. W takich
przypadkach API będzie nadal obecne, ale nie będzie miało żadnego efektu.)
Istnieje wiele implementacji Gateway API,
z których niektóre są specyficzne dla określonych środowisk
chmurowych, inne bardziej skupione na środowiskach "bare metal", a jeszcze inne bardziej ogólne.
Co dalej?
Samouczek Łączenie aplikacji z usługami
pozwala na naukę o Usługach i sieciach Kubernetesa poprzez praktyczne przykłady.
Dokumentacja Sieci Klastra wyjaśnia, jak
skonfigurować sieć dla twojego klastra, a także dostarcza przegląd użytych technologii.
6 - Przechowywanie danych
Trwałe i tymczasowe mechanizmy przechowywania danych dla Podów w klastrze.
7 - Konfiguracja
Zasoby Kubernetesa wykorzystywane do konfiguracji Podów.
8 - Bezpieczeństwo
Zasady ochrony aplikacji cloud-native.
Ta sekcja dokumentacji Kubernetesa ma na celu pomoc w nauce
bezpiecznego uruchamiania workloadów oraz zapoznanie z
podstawowymi aspektami utrzymania bezpieczeństwa klastra Kubernetes.
Kubernetes opiera się na architekturze cloud-native i korzysta z
porad CNCF
dotyczących dobrych praktyk w zakresie bezpieczeństwa informacji cloud-native.
Kubernetes zawiera kilka interfejsów API i mechanizmów bezpieczeństwa, a także sposoby na definiowanie
polityk (ang. policies), które mogą stanowić część tego, jak zarządzasz bezpieczeństwem informacji.
Kubernetes oczekuje, że skonfigurujesz i użyjesz TLS do zapewnienia
szyfrowania przesyłanych danych w obrębie warstwy
sterowania oraz pomiędzy warstwą sterowania a jej klientami. Możesz także włączyć
szyfrowanie danych spoczynkowych dla danych
przechowywanych w obrębie warstwy sterowania Kubernetesa; Nie należy mylić tego z
szyfrowaniem danych w stanie spoczynku dla własnych workloadów, co również może być dobrą praktyką.
Sekrety (ang. Secret)
Obiekt API Secret zapewnia
podstawową ochronę dla wartości konfiguracyjnych, które wymagają poufności.
Ochrona workloadów
Egzekwowanie standardów bezpieczeństwa poda
zapewnia, że Pody i ich kontenery są odpowiednio
izolowane. Możesz również użyć RuntimeClasses
do zdefiniowania niestandardowej izolacji, jeśli tego potrzebujesz.
Polityki sieciowe pozwalają kontrolować
ruch sieciowy pomiędzy Podami lub pomiędzy Podami a siecią poza klastrem.
Możesz wdrażać mechanizmy zabezpieczeń z szerszego ekosystemu, aby wprowadzać środki
zapobiegawcze lub detekcyjne wokół Podów, ich kontenerów oraz obrazów, które w nich działają.
Kontrola przychodzących żądań
Kontrolery przychodzących żądań (Admission controllers
) to wtyczki, które przechwytują żądania do API Kubernetesa i mogą
weryfikować lub modyfikować te żądania w oparciu o konkretne pola w żądaniu. Przemyślane
projektowanie tych kontrolerów pomaga unikać niezamierzonych zakłóceń, szczególnie gdy API
Kubernetesa zmienia się wraz z aktualizacjami. Aby dowiedzieć się więcej, zobacz
Dobre Praktyki dla Admission Webhooks.
Audytowanie
Dziennik audytu Kubernetesa audit logging
dostarcza istotnego z punktu widzenia bezpieczeństwa, chronologicznego zbioru zapisów
dokumentujących sekwencję działań w klastrze. Klastr audytuje aktywności generowane przez
użytkowników, przez aplikacje korzystające z API Kubernetesa oraz przez samą warstwę sterowania.
Zabezpieczenia dostawcy chmury
Informacja: Items on this page refer to vendors external to Kubernetes. The Kubernetes project authors aren't responsible for those third-party products or projects. To add a vendor, product or project to this list, read the content guide before submitting a change. More information.
Jeśli uruchamiasz klaster Kubernetes na własnym sprzęcie lub sprzęcie dostawcy
chmury, zapoznaj się z dokumentacją dotyczącą najlepszych praktyk w zakresie
bezpieczeństwa. Oto linki do dokumentacji bezpieczeństwa niektórych popularnych dostawców chmury:
Możesz definiować zasady bezpieczeństwa, używając mechanizmów natywnych dla
Kubernetesa, takich jak NetworkPolicy
(deklaratywna kontrola nad filtrowaniem pakietów sieciowych) lub
ValidatingAdmissionPolicy (deklaratywne ograniczenia
dotyczące tego, jakie zmiany ktoś może wprowadzać za pomocą API Kubernetesa).
Możesz również polegać na implementacjach polityk z szerszego
ekosystemu wokół Kubernetesa. Kubernetes zapewnia mechanizmy
rozszerzeń, aby umożliwić projektom ekosystemowym wdrażanie
własnych kontroli polityk dotyczących przeglądu kodu źródłowego,
zatwierdzania obrazów kontenerów, kontroli dostępu do API, sieci i innych.
Aby uzyskać więcej informacji na temat mechanizmów polityki i
Kubernetesa, przeczytaj Polityki.
Co dalej?
Dowiedz się więcej na temat powiązanych zagadnień bezpieczeństwa Kubernetesa:
Stosuj polityki do zarządzania bezpieczeństwem i wdrażania najlepszych praktyk.
Polityki Kubernetesa to ustawienia kontrolujące inne konfiguracje lub sposób działania aplikacji w trakcie ich działania. Kubernetes oferuje różne formy polityk, opisane poniżej:
Stosowanie polityk za pomocą obiektów API
Niektóre obiekty API spełniają rolę polityk. Oto kilka przykładów:
NetworkPolicies mogą być używane do ograniczania ruchu przychodzącego i wychodzącego dla workload.
LimitRanges zarządzają ograniczeniami alokacji zasobów w różnych typach obiektów.
Stosowanie polityk za pomocą kontrolerów dopuszczania (ang. Admission Controllers)
Kontroler dopuszczania (ang. Admission Controller - admission controller
) działa na serwerze API i może weryfikować lub modyfikować żądania API. Niektóre takie
kontrolery działają w celu zastosowania polityk. Na przykład kontroler
AlwaysPullImages modyfikuje nowy Pod, aby ustawić politykę pobierania obrazów na Always.
Kubernetes ma kilka wbudowanych kontrolerów dostępu, które można konfigurować za pomocą flagi --enable-admission-plugins serwera API.
Szczegóły dotyczące kontrolerów dopuszczania są udokumentowane w dedykowanej sekcji:
Stosowanie polityk używając ValidatingAdmissionPolicy
Polityki walidacji przyjmowania (ang. Validating admission policies) umożliwiają wykonywanie konfigurowalnych kontroli walidacji na serwerze API przy użyciu wspólnego języka wyrażeń (CEL). Na przykład, ValidatingAdmissionPolicy może być używana do zakazania użycia tagu obrazu latest.
Polityka ValidatingAdmissionPolicy działa na żądaniach API i może być używana do blokowania, audytowania oraz ostrzegania użytkowników o niezgodnych konfiguracjach.
Szczegóły dotyczące API ValidatingAdmissionPolicy, wraz z przykładami, są udokumentowane w dedykowanej sekcji:
Stosowanie polityk przy użyciu dynamicznej kontroli dostępu
Dynamiczne kontrolery dostępu (lub webhooki dostępu) działają poza serwerem API jako oddzielne aplikacje, które rejestrują się do odbierania żądań webhooków w celu przeprowadzania weryfikacji lub modyfikacji żądań API.
Dynamiczne kontrolery dopuszczeń mogą być używane do stosowania polityk na żądaniach API i uruchamiania innych procesów opartych na politykach. Dynamiczny kontroler dopuszczeń może przeprowadzać skomplikowane kontrole, w tym te, które wymagają pobierania innych zasobów klastra i danych zewnętrznych. Na przykład, kontrola weryfikacji obrazu może wyszukiwać dane z rejestrów OCI, aby zatwierdzić podpisy i atestacje obrazów kontenerów.
Szczegóły dotyczące dynamicznej kontroli dostępu są udokumentowane w dedykowanej sekcji:
Informacja: Ta sekcja przekierowuje do projektów zewnętrznych (niżej ich lista alfabetyczna), które udostępniają funkcjonalności wymagane przez Kubernetesa. Autorzy Kubernetesa nie odpowiadają za te projekty. Jeśli chcesz dodać projekt do tego wykazu, zanim wprowadzisz zmiany, przeczytaj nasz przewodnik.
Dynamiczne kontrolery dopuszczeń (Admission Controllers), które działają jako elastyczne silniki polityki, są rozwijane w ekosystemie Kubernetesa:
Menedżery zasobów węzła mogą zarządzać zasobami obliczeniowymi, pamięci oraz urządzeniami dla workloadów krytycznych pod względem opóźnień i o wysokiej przepustowości.
10 - Harmonogramowanie, pierszeństwo i eksmisja
W Kubernetesie, planowanie odnosi się do zapewnienia, że
Pody są dopasowane do Węzłów,
aby kubelet mógł je uruchomić. Pierszeństwo (ang.
preemption) to proces zakończania Podów z niższym
Priorytetem po to, aby Pody z wyższym Priorytetem mogły być
zaplanowane na Węzłach. Eksmisja (ang. eviction) to proces zakończania jednego lub więcej Podów na Węzłach.
Zakłócenie działania Poda to
proces, w ramach którego Pody na węzłach są zakończone dobrowolnie lub mimowolnie.
Dobrowolne zakłócenia są inicjowane celowo przez właścicieli aplikacji lub
administratorów klastra. Mimowolne zakłócenia są niezamierzone i mogą być spowodowane
nieuniknionymi problemami, takimi jak wyczerpanie zasobów na węzłach, lub przypadkowymi usunięciami.
Niskopoziomowe szczegóły istotne dla tworzenia i administracji klastrem Kubernetesa.
Rozdział dotyczący administracji klastrem jest przeznaczony dla każdego, kto tworzy lub zarządza
klastrem Kubernetesa. Zakłada się pewną znajomość podstawowych pojęć Kubernetesa.
Planowanie klastra
Zobacz przewodniki w Od czego zacząć zawierające przykłady planowania, konfiguracji
i uruchamiania klastrów Kubernetes. Rozwiązania wymienione w tym artykule nazywane są dystrybucjami.
Informacja:
Nie wszystkie dystrybucje są aktywnie utrzymywane. Wybierz
dystrybucje, które zostały przetestowane z aktualną wersją Kubernetesa.
Rozważ:
Czy chcesz wypróbować Kubernetesa na swoim komputerze, czy może chcesz zbudować klaster o
wysokiej dostępności, złożony z wielu węzłów? Wybierz dystrybucję najlepiej dostosowaną do Twoich potrzeb.
Czy będziesz korzystać z hostowanego klastra Kubernetesa, takiego jak
Google Kubernetes Engine, czy też hostować własny klaster?
Czy Twój klaster będzie w lokalnym centrum obliczeniowym (on-premises), czy w chmurze (IaaS)?
Kubernetes nie obsługuje bezpośrednio klastrów hybrydowych. Zamiast tego, możesz skonfigurować wiele klastrów.
Jeśli konfigurujesz Kubernetesa lokalnie, zastanów się, który
model sieciowy pasuje najlepiej.
Czy będziesz uruchamiać Kubernetesa na sprzęcie typu "bare metal" czy na maszynach wirtualnych (VM)?
Czy chcesz uruchomić klaster, czy raczej zamierzasz prowadzić
aktywny rozwój kodu projektu Kubernetes? Jeśli to drugie, wybierz dystrybucję aktywnie rozwijaną.
Niektóre dystrybucje używają tylko wydań binarnych, ale oferują większą różnorodność wyboru.
Zapoznaj się z komponentami potrzebnymi do uruchomienia klastra.
Dokument Dobre Praktyki dla Admission Webhooks
opisuje zalecane podejście i ważne aspekty, które należy
uwzględnić przy tworzeniu webhooków modyfikujących oraz wehbooków walidujących w Kubernetesie.
Kubernetes obsługuje węzły działające na systemie Microsoft Windows.
Kubernetes obsługuje węzły
robocze działające zarówno na systemie Linux, jak i Microsoft Windows.
🛇 Ta pozycja przekierowuje do projektu lub produktu, który nie jest częścią projektu Kubernetes. Więcej informacji
CNCF i jej macierzysta organizacja Linux Foundation przyjmują neutralne podejście do
kompatybilności w kontekście dostawców. Możliwe jest dołączenie swojego
serwera Windows jako węzeł roboczy do klastra Kubernetes.
Różne sposoby na modyfikację działania klastra Kubernetesa.
Kubernetes jest wysoce konfigurowalny i rozbudowywalny. W rezultacie
rzadko istnieje potrzeba robienia forka lub przesyłania poprawek do kodu projektu.
Ten przewodnik opisuje opcje dostosowywania klastra Kubernetesa. Jest skierowany do
operatorów klastrów, którzy chcą
zrozumieć, jak dostosować swój klaster Kubernetesa do potrzeb środowiska
pracy. Programiści, którzy są potencjalnymi Deweloperami Platformy
lub
Współtwórcami projektu Kubernetes również uznają go za przydatny jako wprowadzenie
do istniejących punktów rozszerzeń i wzorców oraz ich kompromisów i ograniczeń.
Podejścia do dostosowywania można ogólnie podzielić na konfigurację,
która obejmuje tylko zmiany argumentów wiersza poleceń, lokalnych plików konfiguracyjnych lub
zasobów API; oraz rozszerzenia, które obejmują uruchamianie dodatkowych
programów, dodatkowych usług sieciowych lub obu. Ten dokument dotyczy przede wszystkim rozszerzeń.
Konfiguracja
Pliki konfiguracyjne i argumenty poleceń są udokumentowane w sekcji
Materiały źródłowe (ang. Reference) dokumentacji online, z osobną stroną dla każdego pliku binarnego:
Argumenty poleceń i pliki konfiguracyjne mogą nie zawsze być możliwe do zmiany w
hostowanej usłudze Kubernetesa lub w dystrybucji z zarządzaną instalacją. Kiedy są możliwe do zmiany,
zazwyczaj mogą być zmieniane tylko przez operatora klastra. Dodatkowo, mogą
ulegać zmianom w przyszłych wersjach Kubernetesa, a ich ustawienie może wymagać ponownego uruchomienia
procesów. Z tych powodów należy je używać tylko wtedy, gdy nie ma innych opcji.
Wbudowane interfejsy API polityk, takie jak ResourceQuota,
NetworkPolicy i Role-based Access Control (
RBAC), to natywne API Kubernetesa umożliwiające deklaratywną konfigurację polityk. Interfejsy
API są zazwyczaj użyteczne nawet w przypadku hostowanych usług Kubernetesa i zarządzanych instalacji Kubernetesa.
Wbudowane interfejsy API polityk przestrzegają tych samych konwencji co inne zasoby Kubernetesa, takie jak Pody. Gdy korzystasz
z API polityk, które są stabilne, masz zapewnione
określone wsparcie, zgodnie z ogólną polityką wsparcia API Kubernetesa.
Z tych powodów interfejsy API polityk są zalecane zamiast plików konfiguracyjnych i argumentów poleceń, tam gdzie to możliwe.
Rozszerzenia
Rozszerzenia to komponenty oprogramowania, które rozszerzają i głęboko integrują
się z Kubernetesem. Dostosowują go do obsługi nowych typów i nowych rodzajów sprzętu.
Wielu administratorów klastra korzysta z hostowanej lub dystrybucyjnej instancji Kubernetesa.
Te klastry mają zainstalowane rozszerzenia. W rezultacie, większość użytkowników Kubernetesa
nie będzie musiała instalować rozszerzeń, a jeszcze mniej użytkowników będzie musiało tworzyć nowe.
Wzorce rozszerzeń
Kubernetes jest zaprojektowany tak, aby można go było zautomatyzować poprzez pisanie programów
klienckich. Każdy program, który odczytuje i/lub zapisuje do API
Kubernetesa, może zapewnić użyteczną automatyzację. Automatyzacja może działać zarówno na
klastrze, jak i poza nim. Postępując zgodnie z wytycznymi zawartymi w tym
dokumencie, możesz napisać wysoce dostępną i solidną automatyzację. Automatyzacja generalnie
działa z dowolnym klastrem Kubernetesa, w tym klastrami hostowanymi i zarządzanymi instalacjami.
Istnieje specyficzny wzorzec pisania programów klienckich, które dobrze
współpracują z Kubernetesem, zwany wzorcem
kontrolera. Kontrolery zazwyczaj odczytują .spec obiektu,
ewentualnie wykonują pewne czynności, a następnie aktualizują .status obiektu.
Kontroler jest klientem API Kubernetesa. Gdy Kubernetes działa jako klient i wywołuje zdalną
usługę, nazywa to webhookiem. Zdalna usługa nazywana jest backendem webhooka. Podobnie
jak w przypadku niestandardowych kontrolerów, webhooki stanowią dodatkowy potencjalny punkt awarii.
Informacja:
Poza Kubernetesen, termin "webhook" zazwyczaj odnosi się do mechanizmu
asynchronicznych powiadomień, gdzie wywołanie webhooka służy jako
jednostronne powiadomienie do innego systemu lub komponentu. W ekosystemie
Kubernetesa, nawet synchroniczne wywołania HTTP są często opisywane jako "webhooki".
W modelu webhook Kubernetes wykonuje żądanie sieciowe do zdalnej usługi. W alternatywnym
modelu binarnej wtyczki, Kubernetes wykonuje program binarny. Wtyczki binarne są używane przez
kubelet (na przykład, wtyczki magazynu CSI i
wtyczki sieciowe CNI), oraz
przez kubectl (zobacz Rozszerz kubectl za pomocą wtyczek).
Punkty rozszerzeń
Ten diagram pokazuje punkty rozszerzeń w klastrze
Kubernetesa oraz klientów, którzy uzyskują do niego dostęp.
Punkty rozszerzeń Kubernetesa
Klucz do rysunku
Użytkownicy często wchodzą w interakcję z API Kubernetesa za pomocą kubectl.
Wtyczki dostosowują zachowanie klientów. Istnieją ogólne rozszerzenia,
które mogą być stosowane do różnych klientów, a także specyficzne sposoby rozszerzania kubectl.
Serwer API obsługuje wszystkie żądania. Kilka typów punktów rozszerzeń w serwerze API
umożliwia uwierzytelnianie żądań, blokowanie ich na podstawie ich treści, edytowanie treści oraz
obsługę usuwania. Są one opisane w sekcji Rozszerzenia dostępu do API.
Serwer API obsługuje różne rodzaje zasobów. Wbudowane rodzaje zasobów, takie jak
pods, są definiowane przez projekt Kubernetesa i nie mogą być modyfikowane. Przeczytaj
Rozszerzenia API, aby dowiedzieć się więcej o rozszerzaniu API Kubernetesa.
Scheduler Kubernetesa decyduje,
na których węzłach umieścić pody. Istnieje kilka sposobów na rozszerzenie
harmonogramowania, które są opisane w sekcji Rozszerzenia harmonogramowania.
Duża część zachowań Kubernetesa jest realizowana przez programy zwane
kontrolerami, które są klientami serwera API.
Kontrolery są często używane w połączeniu z niestandardowymi zasobami.
Przeczytaj łączenie nowych API z automatyzacją
oraz Zmiana wbudowanych zasobów, aby dowiedzieć się więcej.
Kubelet działa na serwerach (węzłach) i pomaga podom wyglądać jak
wirtualne serwery z własnymi adresami IP w sieci klastra.
Wtyczki sieciowe umożliwiają różne implementacje sieciowania podów.
Możesz użyć Pluginów Urządzeń, aby zintegrować
niestandardowy sprzęt lub inne specjalne lokalne dla węzła funkcje i udostępnić je Podom
działającym w Twoim klastrze. Kubelet zawiera wsparcie dla pracy z pluginami urządzeń.
Kubelet również montuje i odmontowuje
volume dla podów i ich kontenerów. Możesz użyć
wtyczek magazynowania, aby dodać
obsługę nowych rodzajów magazynu (ang. storage) i innych typów wolumenów.
Schemat przepływu wyboru punktu rozszerzenia
Jeśli nie jesteś pewien, od czego zacząć, ten schemat blokowy może pomóc. Zwróć
uwagę, że niektóre rozwiązania mogą obejmować kilka typów rozszerzeń.
Przewodnik do wyboru metody rozszerzenia
Rozszerzenia klienta
Wtyczki do kubectl to oddzielne pliki binarne, które dodają lub zastępują działanie określonych poleceń. Narzędzie kubectl
może również integrować się z wtyczkami uwierzytelniania.
Te rozszerzenia wpływają tylko na lokalne środowisko danego użytkownika, dlatego nie mogą wymuszać polityk dla całego serwisu.
Definicje zasobów niestandardowych (ang. custom resource)
Rozważ dodanie Custom Resource do Kubernetesa, jeśli chcesz zdefiniować
nowe kontrolery, obiekty konfiguracji aplikacji lub inne deklaratywne
interfejsy API i zarządzać nimi za pomocą narzędzi Kubernetesa, takich jak kubectl.
Aby dowiedzieć się więcej o zasobach niestandardowych, zapoznaj się z przewodnikiem po
zasobach niestandardowych.
Warstwa agregacji API
Możesz użyć warstwy agregacji API Kubernetesa, aby
zintegrować API Kubernetesa z dodatkowymi usługami, takimi jak metryki.
Łączenie nowych interfejsów API z automatyzacją
Kombinacja niestandardowego API zasobu i pętli sterowania nazywana jest wzorcem
controllers. Jeśli Twój kontroler zastępuje ludzkiego
operatora wdrażającego infrastrukturę na podstawie pożądanego stanu,
kontroler może również podążać za wzorcem operatora.
Wzorzec operatora jest używany do zarządzania specyficznymi aplikacjami; zazwyczaj
są to aplikacje, które utrzymują stan i wymagają uwagi w sposobie zarządzania nimi.
Możesz także tworzyć własne niestandardowe interfejsy API i pętle sterujące, które zarządzają
innymi zasobami, takimi jak storage, lub definiować polityki (takie jak ograniczenia kontroli dostępu).
Zmiana wbudowanych zasobów
Kiedy rozszerzasz API Kubernetesa poprzez dodanie zasobów niestandardowych, dodane zasoby
zawsze trafiają do nowych grup API. Nie możesz zastąpić ani zmienić
istniejących grup API. Dodanie API nie pozwala bezpośrednio wpłynąć na zachowanie
istniejących API (takich jak Pody), podczas gdy Rozszerzenia Dostępu do API mogą to zrobić.
Rozszerzenia dostępu do API
Gdy żądanie trafia do serwera API Kubernetesa, najpierw jest
uwierzytelniane, następnie autoryzowane, i podlega różnym typom
kontroli dostępu (niektóre żądania nie są uwierzytelniane i podlegają specjalnemu
przetwarzaniu). Zobacz Kontrolowanie dostępu do API Kubernetesa
aby dowiedzieć się więcej o tym procesie.
Każdy z kroków w przepływie uwierzytelniania / autoryzacji Kubernetesa oferuje punkty rozszerzeń.
Uwierzytelnianie
Uwierzytelnianie mapuje nagłówki
lub certyfikaty we wszystkich żądaniach do nazwy użytkownika dla klienta składającego żądanie.
Kubernetes ma kilka wbudowanych metod uwierzytelniania, które obsługuje. Może również
działać za proxy uwierzytelniającym, a także może wysyłać token z nagłówka Authorization: do
zdalnej usługi w celu weryfikacji (przez authentication webhook
), jeśli te metody nie spełniają Twoich potrzeb.
Autoryzacja
Authorization określa, czy
konkretni użytkownicy mogą odczytywać, zapisywać i wykonywać inne operacje na zasobach
API. Działa na poziomie całych zasobów -- nie rozróżnia na podstawie dowolnych pól obiektu.
Jeśli wbudowane opcje autoryzacji nie spełniają Twoich potrzeb,
webhook autoryzacji umożliwia wywołanie
niestandardowego kodu, który podejmuje decyzję autoryzacyjną.
Dynamiczne sterowanie dostępem
Po autoryzacji żądania, jeśli jest to operacja zapisu, przechodzi również przez
kroki Kontroli Przyjęć (ang. Admission Control).
Oprócz wbudowanych kroków, istnieje kilka rozszerzeń:
Aby podejmować dowolne decyzje dotyczące kontroli dostępu, można użyć ogólnego
webhooka dopuszczenia (ang. Admission webhook).
Webhooki dopuszczenia mogą odrzucać żądania tworzenia lub aktualizacji.
Niektóre webhooki modyfikują dane przychodzącego żądania, zanim zostaną one dalej obsłużone przez Kubernetesa.
Rozszerzenia infrastruktury
Wtyczki urządzeń
Device plugins pozwalają węzłowi na odkrywanie nowych zasobów Węzła (oprócz
wbudowanych, takich jak CPU i pamięć) za pomocą
Device Plugin.
Wtyczki magazynowe (ang. Storage plugins)
Wtyczki Container Storage Interface (CSI)
dostarczają sposób na rozszerzenie Kubernetesa o wsparcie dla nowych rodzajów wolumenów.
Wolumeny mogą być obsługiwane przez trwałe zewnętrzne magazyny danych, dostarczać pamięć ulotną
lub oferować interfejs tylko do odczytu do informacji z wykorzystaniem paradygmatu systemu plików.
Kubernetes zawiera również wsparcie dla wtyczek
FlexVolume, które są przestarzałe od wersji Kubernetes v1.23 (na rzecz CSI).
Wtyczki FlexVolume umożliwiają użytkownikom podłączanie typów woluminów, które nie są natywnie
obsługiwane przez Kubernetesa. Kiedy uruchamiasz Pod, który polega na magazynie FlexVolume, kubelet wywołuje
wtyczkę binarną, aby zamontować wolumin. Zarchiwizowany
FlexVolume projekt wstępny zawiera więcej szczegółów na temat tego podejścia.
Twój klaster Kubernetesa potrzebuje wtyczki sieciowej, aby mieć
działającą sieć Podów i wspierać inne aspekty modelu sieciowego Kubernetesa.
Wtyczki sieciowe
pozwalają Kubernetesowi na współpracę z różnymi topologiami i technologiami sieciowymi.
Wtyczki dostawcy poświadczeń obrazu dla Kubeleta
STATUS FUNKCJONALNOŚCI:Kubernetes v1.26 [stable]
Dostawcy
poświadczeń obrazów dla kubeleta to wtyczki dla kubeleta, które dynamicznie pobierają
poświadczenia rejestru obrazów. Poświadczenia te są następnie używane podczas
pobierania obrazów z rejestrów obrazów kontenerów, które odpowiadają konfiguracji.
Wtyczki mogą komunikować się z zewnętrznymi usługami lub korzystać z lokalnych
plików w celu uzyskania poświadczeń. W ten sposób kubelet nie musi mieć statycznych
poświadczeń dla każdego rejestru i może obsługiwać różne metody i protokoły uwierzytelniania.
Scheduler to specjalny typ kontrolera, który obserwuje pody i
przypisuje pody do węzłów. Domyślny scheduler może być całkowicie
zastąpiony, przy jednoczesnym dalszym korzystaniu z innych
komponentów Kubernetesa, lub wielokrotne schedulery
mogą działać jednocześnie.
Jest to duże przedsięwzięcie i prawie wszyscy użytkownicy
Kubernetesa stwierdzają, że nie muszą modyfikować schedulera.
Możesz kontrolować, które wtyczki planowania są
aktywne, lub kojarzyć zestawy wtyczek z różnymi nazwanymi
profilami schedulera. Możesz również napisać własną wtyczkę, która integruje się z jednym lub więcej
punktami rozszerzeń kube-schedulera.
Wreszcie, wbudowany komponent kube-scheduler obsługuje
webhook,
który pozwala zdalnemu backendowi HTTP (rozszerzenie schedulera) na
filtrowanie i/lub priorytetyzowanie węzłów, które kube-scheduler wybiera dla poda.
Informacja:
Za pomocą webhooka rozszerzającego harmonogram można wpływać
jedynie na filtrowanie węzłów i priorytetyzację węzłów; inne
punkty rozszerzenia nie są dostępne poprzez integrację webhooków.
Co dalej?
Dowiedz się więcej o rozszerzeniach infrastruktury
Niestandardowe zasoby Kubernetesa (ang. Custom Resources) stanowią rozszerzenie API. Kubernetes udostępnia dwie metody ich integracji z klastrem:
Mechanizm CustomResourceDefinition
(CRD) pozwala deklaratywnie zdefiniować nowe niestandardowe API z
grupą API, rodzajem i schematem, który określisz. Warstwa sterowania Kubernetesa
obsługuje i zarządza przechowywaniem twojego niestandardowego zasobu. CRD pozwalają tworzyć
nowe typy zasobów dla twojego klastra bez pisania i uruchamiania niestandardowego serwera API.
Warstwa agregacji
znajduje się za głównym
serwerem API, który działa jako proxy. To rozwiązanie nazywa się
Agregacją API (AA), które umożliwia dostarczanie implementacji dla
własnych niestandardowych zasobów poprzez napisanie i
wdrożenie własnego serwera API. Główny serwer API deleguje
żądania do twojego serwera API, udostępniając je wszystkim jego klientom.
13.2 - Rozszerzenia obliczeniowe, przechowywania danych i sieciowe
Ta sekcja obejmuje rozszerzenia do Twojego klastra, które nie
są częścią samego Kubernetesa. Możesz użyć tych rozszerzeń,
aby ulepszyć węzły w Twoim klastrze lub zapewnić sieć łączącą Pody.
Wtyczki Container Storage Interface (CSI)
dostarczają sposób na rozszerzenie Kubernetesa o wsparcie dla nowych rodzajów wolumenów. Wolumeny
mogą być wspierane przez trwałe zewnętrzne systemy przechowywania, mogą dostarczać pamięć
ulotną, lub mogą oferować interfejs tylko do odczytu dla informacji przy użyciu paradygmatu systemu plików.
Kubernetes zawiera również wsparcie dla wtyczek
FlexVolume, które są przestarzałe od Kubernetesa v1.23 (na rzecz CSI).
Wtyczki FlexVolume pozwalają użytkownikom montować typy woluminów, które nie są
natywnie obsługiwane przez Kubernetesa. Gdy uruchamiasz Pod, który polega na
przechowywaniu FlexVolume, "kubelet" wywołuje binarną wtyczkę, aby zamontować wolumin.
Zarchiwizowany FlexVolume
dokument projektowy zawiera więcej szczegółów na temat tego podejścia.
Wtyczki urządzeń umożliwiają węzłowi odkrywanie nowych funkcji węzła
(dodatkowo do wbudowanych zasobów węzła, takich jak cpu i memory), oraz
udostępniają te niestandardowe funkcje lokalne węzła dla Podów, które ich żądają.
Wtyczki sieciowe (ang. network plugins) umożliwiają Kubernetesowi obsługę różnych topologii i
technologii sieciowych. Aby klaster Kubernetesa miał działającą sieć Podów i wspierał różne
elementy modelu sieciowego Kubernetesa, konieczne jest zainstalowanie odpowiedniej wtyczki sieciowej.
Kubernetes 1.33 jest kompatybilny z
wtyczkami sieciowymi CNI.